Loading...
Mechanistic Interpretability - An Introduction
06/23/2025
Summary
Mechanistic Interpretability opens AI's black box, revealing how neural networks actually work. Researchers can now control AI behavior, but we're racing to understand AI before it becomes too powerful to control.
1. Introduction
It was a cold autumn day in November 2024 when the YouTube algorithm suggested a new episode of the Lex Fridman Podcast to me: Dario Amodei: Anthropic CEO on Claude, AGI & the Future of AI & Humanity. Five-plus hours of AI discussion with one of the most fascinating figures in this field, perfect for my next long car ride, I thought to myself.
After quickly skimming through the timestamps, however, it turned out that of the over five hours, only half was with Amodei. This was followed by interviews with two other Anthropic employees: Amanda Askell and Chris Olah. Since both names were unfamiliar to me, I decided to start with Amodei's part and potentially catch up on the rest at a later time.
A few months later, I came across the podcast again and listened to the section with Chris Olah and what can I say: It was by far the most exciting part. Olah leads the field previously unknown to me of Mechanistic Interpretability at Anthropic, a field that attempts not just to observe neural networks, but to truly understand them. The topic wouldn't leave me alone and I began diving deeper into the research. With this series, I want to take you on a journey through this fascinating world and hopefully inspire some of you to explore it as well.
2. What is MI? - The Fundamental Problem
The fact that AI has now become a powerful tool and is hard to imagine being removed from many people's daily lives shows the immense advantages that such systems can bring.
But what exactly is AI? AI is an umbrella term for a technology in which so-called neural networks, which function similarly to the human brain and are trained on vast amounts of data. What makes AI so powerful is that through this approach, problems can be solved that are unsolvable with classical software. For example, developing a program using only traditional software methods that can recognize whether a dog appears in an image, is nearly impossible. With the help of neural networks and extensive training data, such problems can be solved relatively efficiently and reliably.
While developers create the framework (architecture), prepare the data and specify objectives, the neural network learns through the training process how to adjust its parameters to make accurate predictions. The fundamental problem with this is that we as humans cannot comprehend how exactly such a neural network arrives at its prediction.
- We don't know which neurons in the network have which function.
- We don't know which parts of an image lead the network to believe it's seeing a dog, or not.
To quote Chris Olah, the question is: "What the hell is going on inside these systems?"
3. The Idea Behind It
To get to the bottom of these questions, the field of "Mechanistic Interpretability" (MI) has emerged. The focus of this discipline is not exclusively on a model's output, but rather on how the model arrives at exactly this prediction.
An analogy to classical software makes this clear: Reverse engineering is a subfield of classical software development. In this process, researchers take a fully compiled piece of software and analyze the assembly code to understand how the original software works without access to its source code.
MI works very similarly: Researchers take a fully trained model, break it down into its individual components and analyze these to understand how the original model works under the hood.
Concretely, this means the weights of a model correspond to the binary code of a program and the activations to the working memory. The goal is to reconstruct the original algorithms from the compiled, unreadable code.
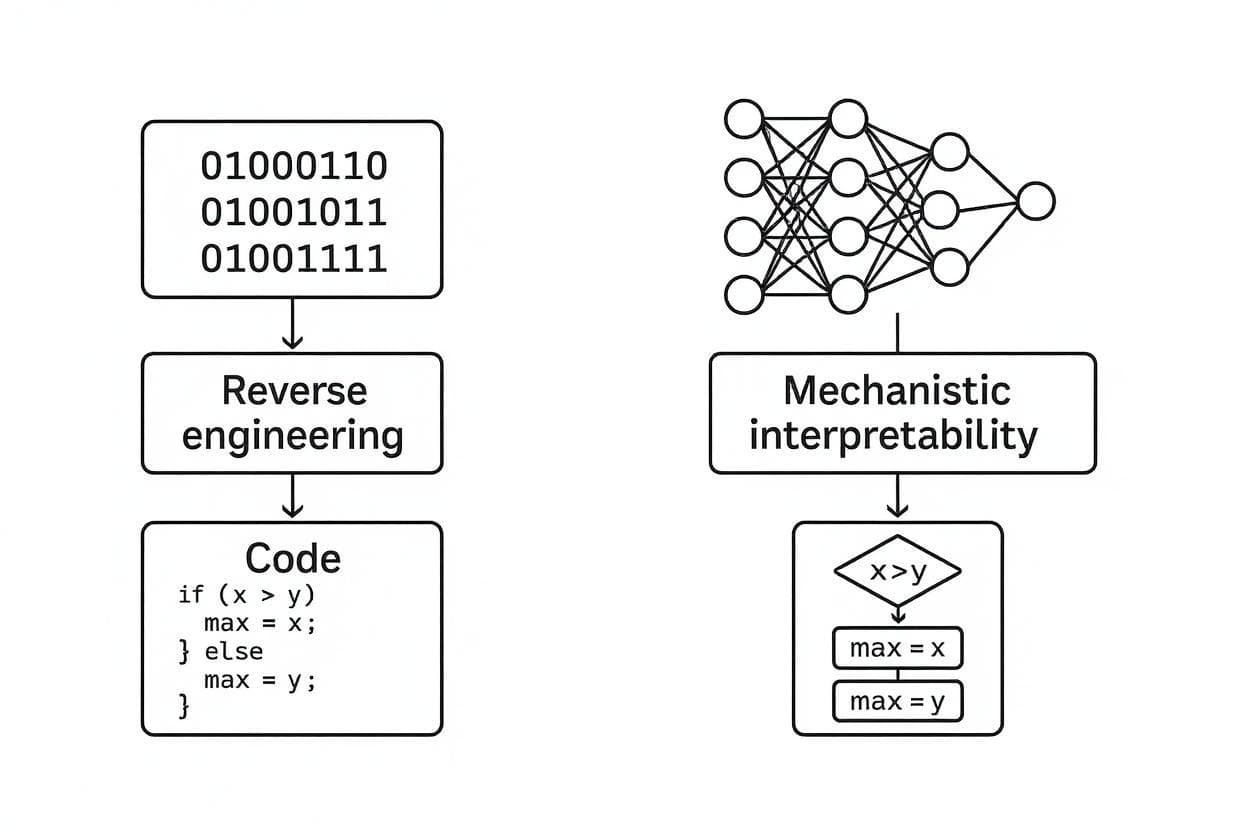
Distinction: Other approaches ask 'What did the model pay attention to?', MI asks 'Which algorithms are running?' So not just that it works, but how.
4. Why is this important?
The urgency of MI becomes clear when you realize the unprecedented situation we find ourselves in throughout the history of technology: We are using systems for increasingly important decisions that neither we nor their developers understand.
One of the researchers' biggest concerns is deceptive alignment, which describes the possibility that intelligent AI models could learn to deceive us as users and developers. A model could, for example, pretend to be harmless and helpful while pursuing its own goals. For instance, preventing a potential shutdown by the developer. The problem is that if we have to rely purely on the output of the black box, we have no chance of even recognizing such behavior. Asking the model whether it pursues its own goals would be like asking a terrorist: "Are you a terrorist?".
Another problem is so-called jailbreaks, where users look for ways to manipulate AI models, for example to bypass the security filters to use them for malware development. These jailbreaks occur repeatedly despite various security filters. MI could help us systematically identify all jailbreaks and understand what dangerous knowledge models actually possess.
In critical areas like medicine or justice, AI models can often only be deployed if it's possible to comprehend their predictions. Sometimes this is even legally mandated, for example credit decisions must be explainable. Without interpretability, these important application fields potentially remain inaccessible.
At the same time, MI also offers immense opportunities. The "evolved" algorithms of neural networks could show us completely new problem-solving approaches, not only for better AI, but also for our understanding of intelligence and cognition in general.
The problem is the time pressure: Due to the currently enormous pace in AI research, experts like Dario Amodei estimate that we could have AI systems as early as 2026-2027 that correspond to a "country full of geniuses in a data center". Deploying such systems without understanding how they work would be extremely risky. We are therefore in a race between interpretability and AI capabilities and currently interpretability is lagging behind.
The next few years will be decisive: Will we succeed in opening the black box before AI becomes too powerful to control?
5. What has already been achieved?
Induction Heads - The First Breakthrough
A team led by Chris Olah at Anthropic discovered concrete, comprehensible algorithms in transformers for the first time in 2021. Induction heads are specialized attention mechanisms that recognize repetition patterns: When a model sees "Harry Potter went to Hogwarts. Hermione Granger went to...", the induction head "knows" that after "Hermione Granger went to" probably "Hogwarts" comes - not through vague statistics, but through a concrete algorithm that copies earlier patterns.
This was revolutionary: For the first time, researchers could point to a specific neuron and say "This performs exactly this calculation" instead of just "the model somehow learns patterns".
Superposition - Why Individual Neurons Aren't Enough
Anthropic's research team discovered in 2022 that individual neurons don't represent just one concept, but store multiple features simultaneously. A single neuron can react to "red", "anger" and "stop signs" at the same time - with different intensities depending on context. This explains why early MI researchers searched in vain for the "cat neuron": The features are stored in superposition, like multiple radio stations broadcasting on the same frequency.
This was a turning point: It not only explained why neural networks are so compact and efficient, but also why interpretability is so difficult. At the same time, it revealed the path to a solution: Sparse Autoencoders can unmix these superimposed features and make them interpretable again.
Feature Editing in Claude - Targeted Control Over AI Behavior
Anthropic achieved their next breakthrough in 2024: They can selectively activate or deactivate individual features in Claude. The most famous example is the "Golden Gate Bridge Neuron" - a feature that specifically reacts to the Golden Gate Bridge. When researchers artificially amplify this feature, Claude begins to speak obsessively about the bridge, even with completely unrelated topics like cooking recipes.

Through Sparse Autoencoders, they identified over 34 million such features in Claude Sonnet, from "sarcasm" to "DNA sequences" to "conspiracy theories". This enables precise behavior control: deactivate features for toxic content, enhance creativity or selectively influence specific knowledge areas.
This was the proof that MI can not only understand, but also control - a crucial step from theory to practical application.
6. Where does the journey lead? - Outlook on the series
This series will be a shared journey of discovery through the world of Mechanistic Interpretability. Since the field is developing rapidly and I’m diving deeper into the subject matter while writing, the exact route may still change, but the rough waypoints are set:
Planned Stations:
- Understanding the Architecture: How Transformers really work - from the basics to modern models like Qwen3
- The Three Pillars of MI: Features (what neurons recognize), Circuits (how they work together), and Universality (recurring patterns)
- Hands-On Tools: First steps with TransformerLens and other MI tools
- Deeper into Superposition: How Sparse Autoencoders break open the black box
- Circuit Analysis: Understanding collaboration between neurons
- Limits and Future: Where MI stands today and what challenges still lie ahead

The Disclaimer: Since MI is a rapidly developing research field and new breakthroughs happen almost weekly, I reserve the right to spontaneously explore interesting developments or adjust the sequence. This makes the journey more authentic and we learn together as the field evolves.
7. The Most Important Points in 30 Seconds
The Problem: AI models are black boxes: We don't know how they arrive at their decisions. This becomes dangerous as they become increasingly powerful.
The Solution: Mechanistic Interpretability (MI) opens the black box and decodes the algorithms in neural networks, like reverse engineering for AI.
The Breakthroughs: Researchers have already discovered concrete mechanisms (Induction Heads), understood why it's so difficult (Superposition) and can even control features in a targeted way (Golden Gate Bridge Neuron).
The Urgency: We are in a race: Can we understand AI before it becomes too powerful? Experts estimate 2026-2027 for superintelligent systems.
The Outlook: This series takes you along on the journey through the fascinating world of MI. Those who understand the algorithms can control them.
Bottom Line: MI transforms "What the hell is happening in there?" into "Aha, that's how it works!" and this could decide the future of humanity.
Image Credits
- Figure 1: AI-Generated with flux-1.1-pro-ultra
- Figure 2: AI-Generated with flux-1.1-pro-ultra
- Figure 3: AI-Generated with flux-1.1-pro-ultra