Loading...
Mechanistic Interpretability - Eine Einführung
23.06.2025
Zusammenfassung
Mechanistic Interpretability öffnet die Black Box der KI und zeigt, wie neuronale Netze wirklich funktionieren. Forscher können nun KI-Verhalten kontrollieren, aber wir rennen gegen die Zeit, bevor KI zu mächtig wird.
1. Einführung
Es war ein kalter Herbsttag im November 2024, als der YouTube-Algorithmus mir eine neue Folge des Lex Fridman Podcasts vorschlug: Dario Amodei: Anthropic CEO on Claude, AGI & the Future of AI & Humanity. Über fünf Stunden KI-Talk mit einem der interessantesten Personen dieses Feldes, perfekt für die nächste lange Autofahrt, dachte ich mir.
Nach einem schnellen Überfliegen der Timestamps stellte sich jedoch heraus, dass von den über fünf Stunden lediglich die Hälfte mit Amodei war. Danach folgten Interviews mit zwei weiteren Anthropic-Mitarbeitern: Amanda Askell und Chris Olah. Da mir beide Namen bis dato unbekannt waren, beschloss ich zunächst nur den Teil von Amodei anzuhören und den Rest gegebenenfalls zu einem späteren Zeitpunkt.
Ein paar Monate später stieß ich dann erneut auf den Podcast und hörte mir den Abschnitt mit Chris Olah an und was soll ich sagen: Es war der mit Abstand spannendste Teil. Olah leitet bei Anthropic den mir zuvor unbekannten Bereich Mechanistic Interpretability, ein Feld, das versucht, neuronale Netze nicht nur zu beobachten, sondern wirklich zu verstehen. Das Thema ließ mich nicht mehr los und ich begann zu recherchieren. Mit dieser Serie möchte ich euch auf eine Reise durch diese faszinierende Welt nehmen und hoffentlich den ein oder anderen ebenfalls dafür begeistern.
2. Was ist MI? - Das Grundproblem
Dass KI mittlerweile ein mächtiges Instrument geworden ist und sich aus dem Alltag vieler kaum mehr wegzudenken lässt, zeigt die immensen Vorteile, die solche Systeme bringen können.
Doch was ist KI eigentlich? KI ist ein Oberbegriff für eine Technik, bei der sogenannte neuronale Netze, die ähnlich wie das menschliche Gehirn funktionieren, mit sehr großen Datenmengen trainiert werden. Was KI so mächtig macht, ist die Tatsache, dass durch dieses Vorgehen Probleme gelöst werden können, die mit klassischer Software unlösbar sind. Beispielsweise ist es nahezu unmöglich mit klassischer Softwareentwicklung ein Programm zu entwickeln, welches erkennen soll, ob auf einem Bild ein Hund zu sehen ist. Mithilfe neuronaler Netze und vieler Trainingsdaten lassen sich solche Probleme relativ effizient und zuverlässig lösen.
Der Entwickler erschafft zwar am Anfang das Gerüst (Architektur), bereitet die Daten vor und gibt ein Ziel an. Aber anschließend lernt das neuronale Netz durch den Trainingsvorgang, wie es seine Parameter anpassen muss, um gute Vorhersagen treffen zu können. Das fundamentale Problem dabei ist, dass wir als Menschen nicht nachvollziehen können, wie genau ein solches neuronales Netz zu seiner Vorhersage kommt.
Wir wissen nicht, welche Neuronen im Netz welche Funktion haben.
Wir wissen nicht, welcher Teil eines Bildes das Netz glauben lässt, es handle sich um einen Hund in dem Bild, oder auch nicht.
Um Chris Olah zu zitieren: Die Frage ist: "Was zum Teufel geht in diesen Systemen vor?“
3. Die Idee dahinter
Um diesen Fragen auf den Grund zu gehen, hat sich der Bereich “Mechanistic Interpretability” (MI) gebildet. Der Fokus in dieser Disziplin liegt nicht ausschließlich auf dem Output eines Modells, sondern vielmehr auf der Art, wie das Modell zu genau dieser Vorhersage kommt.
Eine Analogie zur klassischen Software macht das deutlich:
Reverse Engineering ist ein Unterfeld der klassischen Softwareentwicklung. Dabei nehmen Forscher eine fertig kompilierte Software und analysieren den Assembly-Code, um zu verstehen, wie die ursprüngliche Software funktioniert, ohne deren Quellcode zu kennen.
Bei MI verläuft es sehr ähnlich: Die Forscher nehmen ein fertig trainiertes Modell, zerlegen es in seine Einzelteile und analysieren diese, um zu verstehen, wie das ursprüngliche Modell unter der Haube funktioniert.
Konkret bedeutet das: Die Gewichte eines Modells entsprechen dem Binärcode eines Programms und die Aktivierungen dem Arbeitsspeicher. Das Ziel ist es, aus dem kompilierten, unlesbaren Code die ursprünglichen Algorithmen zu rekonstruieren.
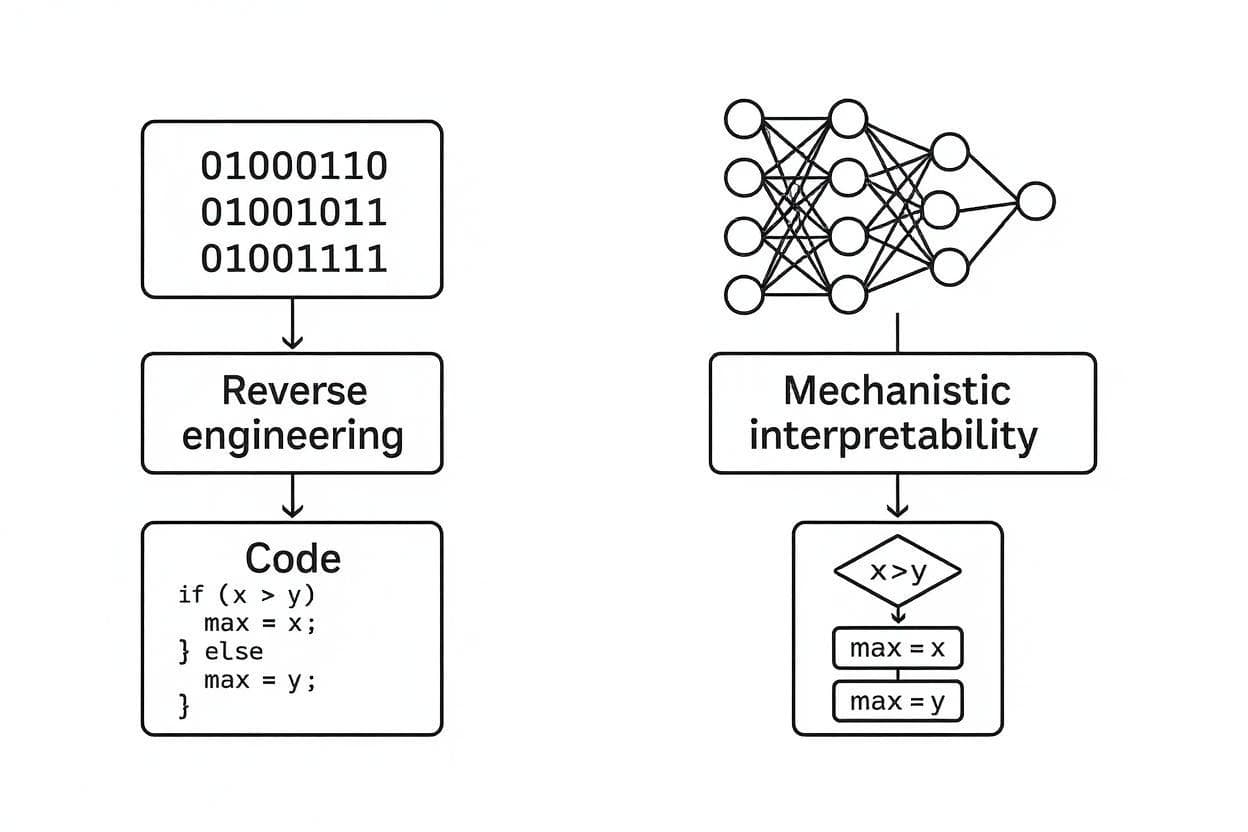
Abgrenzung: Andere Ansätze fragen 'Worauf hat das Modell geachtet?', MI fragt 'Welche Algorithmen laufen ab?' Also nicht nur dass es funktioniert, sondern wie.
4. Warum ist das wichtig?
Die Dringlichkeit von MI wird deutlich, wenn man sich mal bewusst macht, in welch beispielloser Situation in der Technologiegeschichte wir uns befinden: Wir nutzen Systeme für zunehmend mehr und wichtigere Entscheidungen, die weder wir noch deren Entwickler verstehen.
Eine der größten Sorgen der Forscher ist deceptive alignment, was die Möglichkeit beschreibt, dass intelligente KI-Modelle lernen könnten uns als Nutzer und Entwickler zu täuschen. Ein Modell könnte beispielsweise vortäuschen harmlos und hilfreich zu sein, während es eigene Ziele verfolgt. Beispielsweise die Verhinderung einer potenziellen Abschaltung durch den Entwickler. Das Problem dabei ist, dass wenn wir rein auf die Ausgabe der Blackbox vertrauen müssen, wir keine Chance haben ein solches Verhalten überhaupt zu erkennen. Das Modell zu fragen, ob es eigene Ziele verfolgt, hätte es die gleiche Wirkung, einen Terroristen zu fragen: “Sind Sie ein Terrorist?”.
Ein weiteres Problem sind sogenannte Jailbreaks, bei denen Nutzer Wege suchen, die KI-Modelle zu manipulieren, beispielsweise um die Sicherheitsfilter solcher Modelle zu umgehen, um diese für Malware-Entwicklung zu nutzen. Diese Jailbreaks treten trotz verschiedener Sicherheitsfilter immer wieder auf. MI könnte uns dabei helfen, systematisch alle Jailbreaks zu identifizieren und zu verstehen, welches gefährliche Wissen Modelle überhaupt besitzen.
In kritischen Bereichen wie der Medizin oder der Justiz können KI-Modelle oftmals nur eingesetzt werden, wenn es möglich ist, ihre Vorhersagen nachvollziehen zu können. Teilweise ist dies sogar rechtlich vorgeschrieben, beispielsweise müssen Kreditentscheidungen erklärbar sein. Ohne Interpretability bleiben diese wichtigen Anwendungsfelder potenziell verschlossen.
Gleichzeitig bietet MI aber auch immense Chancen. Die "gezüchteten" Algorithmen neuronaler Netze könnten uns völlig neue Problemlösungsansätze zeigen, nicht nur für bessere KI, sondern auch für unser Verständnis von Intelligenz und Kognition allgemein.
Das Problem ist der Zeitdruck: Durch das momentan enorme Tempo in der KI-Forschung schätzen Experten wie Dario Amodei, dass wir bereits 2026-2027 KI-Systeme haben könnten, die einem "Land voller Genies in einem Rechenzentrum" entsprechen. Solche Systeme ohne Verständnis ihrer Funktionsweise zu deployen, wäre extrem riskant. Wir befinden uns daher in einem Wettlauf zwischen Interpretability und KI-Fähigkeiten und aktuell liegt die Interpretability zurück.
Die nächsten Jahre werden entscheidend sein: Gelingt es uns, die Blackbox zu öffnen, bevor KI zu mächtig wird, um kontrolliert zu bleiben?
5. Was wurde schon erreicht?
Induction Heads - Der erste Durchbruch
Ein Team rund um Chris Olah von Anthropic entdeckte 2021 zum ersten Mal konkrete, nachvollziehbare Algorithmen in Transformern. Induction Heads sind spezialisierte Attention-Mechanismen, die Wiederholungsmuster erkennen: Wenn ein Modell "Harry Potter ging nach Hogwarts. Hermine Granger ging nach..." sieht, "weiß" der Induction Head, dass nach "Hermine Granger ging nach" wahrscheinlich "Hogwarts" kommt - nicht durch vage Statistik, sondern durch einen konkreten Algorithmus, der frühere Muster kopiert.
Das war revolutionär: Zum ersten Mal konnten Forscher auf ein spezifisches Neuron zeigen und sagen "Das hier führt exakt diese Berechnung aus" statt nur "das Modell lernt irgendwie Muster".
Superposition - Warum einzelne Neuronen nicht reichen
Anthropics Forschungsteam entdeckte 2022, dass einzelne Neuronen nicht nur ein Konzept repräsentieren, sondern mehrere Features gleichzeitig speichern. Ein einzelnes Neuron kann gleichzeitig auf "rot", "Wut" und "Stopp-Schilder" reagieren - je nach Kontext unterschiedlich stark. Das erklärt, warum frühe MI-Forscher vergeblich nach dem "Katzen-Neuron" suchten: Beim Konzept der Superposition überlagern sich einzelne Features, wie mehrere Radiosender auf derselben Frequenz.
Das war ein Wendepunkt: Es erklärte nicht nur, warum neuronale Netze so kompakt und effizient sind, sondern auch warum Interpretability so schwierig ist. Gleichzeitig zeigte es den Weg zur Lösung - Sparse Autoencoders können diese überlagerten Features wieder entmischen und interpretierbar machen.
Feature Editing in Claude - Gezielte Kontrolle über KI-Verhalten
Anthropic gelang 2024 der nächste Durchbruch: Sie können einzelne Features in Claude gezielt aktivieren oder deaktivieren. Das berühmteste Beispiel ist das "Golden Gate Bridge Neuron" - ein Feature, das spezifisch auf die Golden Gate Bridge reagiert. Verstärken die Forscher dieses Feature künstlich, beginnt Claude obsessiv über die Brücke zu sprechen, selbst bei völlig unverwandten Themen wie Kochrezepten.

Durch Sparse Autoencoders identifizierten sie über 34 Millionen solcher Features in Claude Sonnet, von "Sarkasmus" über "DNA-Sequenzen" bis hin zu "Verschwörungstheorien". Das ermöglicht präzise Verhaltenssteuerung: Features für toxische Inhalte deaktivieren, Kreativität verstärken oder spezifische Wissensbereiche gezielt beeinflussen.
Das war der Beweis, dass MI nicht nur verstehen, sondern auch kontrollieren kann - ein entscheidender Schritt von der Theorie zur praktischen Anwendung.
6. Wohin führt die Reise? – Ausblick auf die Serie
Diese Serie wird eine gemeinsame Entdeckungsreise durch die Welt der Mechanistic Interpretability. Da sich das Feld rasant entwickelt und ich selbst beim Schreiben tiefer in die Materie eintauche, kann sich die genaue Route noch ändern, aber die groben Wegpunkte stehen fest:
Geplante Stationen:
- Die Architektur verstehen: Wie Transformer wirklich funktionieren: Von den Grundlagen bis zu modernen Modellen wie Qwen3
- Die drei Säulen der MI: Features (was Neuronen erkennen), Circuits (wie sie zusammenarbeiten) und Universality (wiederkehrende Muster)
- Hands-On Tools: Erste Schritte mit TransformerLens und anderen MI-Werkzeugen
- Tiefer in Superposition: Wie Sparse Autoencoders die Blackbox aufbrechen
- Circuit Analysis: Die Zusammenarbeit zwischen Neuronen verstehen
- Grenzen und Zukunft: Wo MI heute steht und welche Herausforderungen noch warten

Der Disclaimer: Da MI ein sich rasant entwickelndes Forschungsfeld ist und neue Durchbrüche fast wöchentlich passieren, behalte ich mir vor, interessante Entwicklungen spontan aufzugreifen oder die Reihenfolge anzupassen. Das macht die Reise authentischer und wir lernen gemeinsam, während das Feld sich entwickelt.
7. Das Wichtigste in 30 Sekunden
Das Problem: KI-Modelle sind Blackboxes: Wir wissen nicht, wie sie zu ihren Entscheidungen kommen. Das wird gefährlich, wenn sie immer mächtiger werden.
Die Lösung: Mechanistic Interpretability (MI) öffnet die Blackbox und entschlüsselt die Algorithmen in neuronalen Netzen, wie Reverse Engineering für KI.
Die Durchbrüche: Forscher haben bereits konkrete Mechanismen entdeckt (Induction Heads), verstanden, warum es so schwer ist (Superposition) und können sogar Features gezielt steuern (Golden Gate Bridge Neuron).
Die Dringlichkeit: Wir befinden uns in einem Wettlauf: Können wir KI verstehen, bevor sie zu mächtig wird? Experten schätzen 2026-2027 für superintelligente Systeme.
Der Ausblick: Diese Serie nimmt euch mit auf die Reise durch die faszinierende Welt der MI. Wer die Algorithmen versteht, kann sie kontrollieren.
Bottom Line: MI verwandelt "Was zur Hölle passiert da drinnen?" in "Aha, so funktioniert das!" und das könnte über die Zukunft der Menschheit entscheiden.
Bildquellen
- Abb. 1: Erstellt mit KI (flux-1.1-pro-ultra)
- Abb. 2: Erstellt mit KI (flux-1.1-pro-ultra)
- Abb. 3: Erstellt mit KI (flux-1.1-pro-ultra)